This integration is powered by Singer's Braintree tap. For support, visit the GitHub repo or join the Singer Slack.
Braintree integration summary
Stitch’s Braintree integration replicates data using the Braintree API . Refer to the Schema section for a list of objects available for replication.
Braintree feature snapshot
A high-level look at Stitch's Braintree integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release Status |
Released |
Supported By | |
| Stitch Plan |
Free |
Singer GitHub Repository | |
| DATA SELECTION | |||
| Table Selection |
Unsupported |
Column Selection |
Unsupported |
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Unsupported |
| Table-level Reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting Braintree
Braintree setup requirements
To set up Braintree in Stitch, you need:
-
Access to a Production Braintree account. Stitch does not currently support connecting to Sandbox accounts.
-
Super Admin and API Access permissions in Braintree. This is required to create the API access token in Braintree. You can find info on Braintree user roles and permissions here.
Additionally, Stitch’s Braintree integration will only replicate transactions for the default merchant account in your Braintree instance. You can verify the merchant account set as the default by going to Settings > Processing > Merchant Accounts when signed into Braintree.
Step 1: Whitelist Stitch's IP addresses in Braintree
This step may not be required.
This step is only required if you restrict IP access to your Braintree account.
If you don’t use this feature, skip to the next section.
- Sign into your Braintree account.
- Click Settings > Security.
- In the Security Options page, click Edit in the IP and Hostname Restrictions section.
-
In the IP Address or Hostname field, paste one of the IP addresses from the following list:
-
52.23.137.21/32
-
52.204.223.208/32
-
52.204.228.32/32
-
52.204.230.227/32
-
- Check the Allow API Access box.
- Click Add Allowed Host.
- Repeat steps 4-6 for each Stitch IP address in the list above.
- After all of Stitch’s IP addresses have been added, click Enable Restrictions.
Step 2: Retrieve your Braintree API credentials
- If you haven’t already, sign into your Braintree account.
- Click Account > My User.
- Scroll down to the API Keys, Tokenization Keys, Encryption Keys section and click View Authorizations.
- In the API Keys section, click Generate New API Key.
- After the key has been generated, click the View link in the Private Key column.
-
This will display the Client Library Key page, which contains your Braintree API credentials:
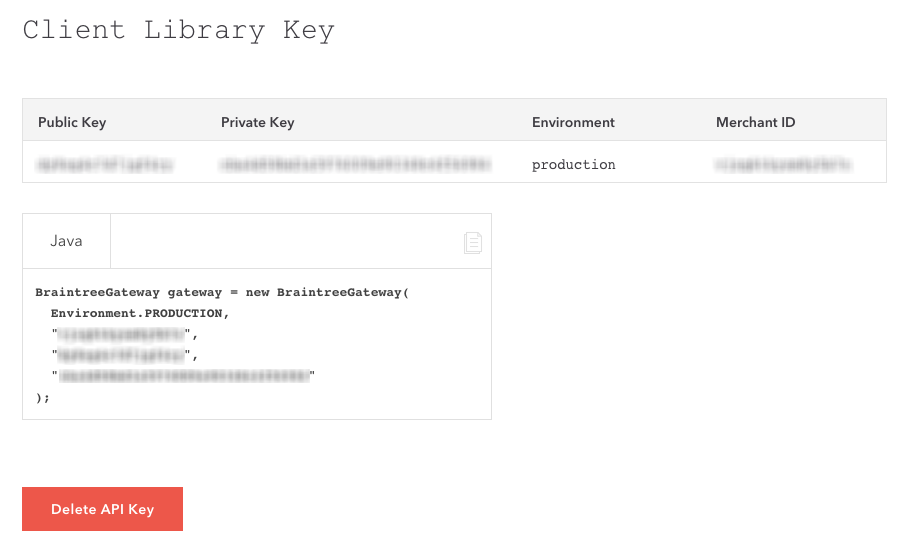
Leave the Braintree Client Library Key page open for now - you’ll need the Public Key, Private Key, and Merchant ID to complete the setup in Stitch.
Step 3: Add Braintree as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the Braintree icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch Braintree” would create a schema called
stitch_braintreein the destination. Note: Schema names cannot be changed after you save the integration. - In the Merchant ID field, paste your Braintree Merchant ID.
- In the Public Key field, paste your Braintree Public Key.
- In the Private Key field, paste your Braintree Private Key.
Step 4: Define the historical sync
The Sync Historical Data setting will define the starting date for your Braintree integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond Braintree’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 5: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
Braintree integrations support the following replication scheduling methods:
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Initial and historical replication jobs
After you finish setting up Braintree, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
Braintree table schemas
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
transactions
| Replication Method : |
Key-based Incremental |
Replication Key |
created_at |
|
Primary Key |
id |
API endpoint : |
The transactions table contains info about the transactions in your Braintree account, including the transaction’s status.
Transaction Data & Default Merchant Accounts
Our Braintree integration will only replicate transactions for the default merchant account in your Braintree instance. You can verify the merchant account set as the default by going to Settings > Processing > Merchant Accounts when signed into Braintree.
|
id
The ID of the transaction. |
||
|
created_at
The datetime when the transaction was created. |
||
|
updated_at
The datetime when the transaction was most recently updated. |
||
|
settlement_batch_id
The ID of the settlement batch that the transaction was processed in. |
||
|
status
The status of the transaction. For example: |
||
|
type
Indicates if a transaction is a sale or credit. |
||
|
amount
The amount of the transaction. |
||
|
service_fee_amount
The portion of a sub-merchant’s transaction revenue that was routed to the master merchant account. |
||
|
order_id
The order ID of the transaction. |
||
|
plan_id
The plan ID. |
||
|
gateway_rejection_reason
Indicates the reason for a status of |
||
|
processor_authorization_code
The authorization code returned by the processor. |
||
|
processor_response_code
The processor response code. |
||
|
processor_response_text
The processor response text. |
||
|
recurring
Indicates if the transaction was passed with a recurring ecommerce indicator (ECI) flag. |
||
|
refunded_transaction_id
The sale transaction ID associated with a refund transaction. |
||
|
currency_iso_code
The currency for the transaction. For example: |
||
|
customer_details
The customer details used to process the transaction.
|
||
|
credit_card_details
Details about the credit card associated with the transaction.
|
||
|
subscription_details
Details about the subscription associated with the transaction.
|
||
|
disbursement_details
Details about how the transaction was disbursed.
|
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.