Data.world helps you host and share your data, collaborate with your team, and capture context and conclusions as you work.
Pricing
Data.world plans vary depending on the number of private projects/data sets, size limits per project/dataset, external integrations, and total number of team members that can belong to an account. All plans, however, include unlimited public projects/datasets, API access, joins, queries, activity alerts, and other standard features.
While Stitch is compatible with all of data.world plans, keep in mind that the number of private projects/datasets and the size maximum of those projects varies by plan.
For more information on data.world’s plans, refer to their pricing page.
Setup
With just a few clicks, you can connect your data.world account to Stitch and get the data flowing.
Replication
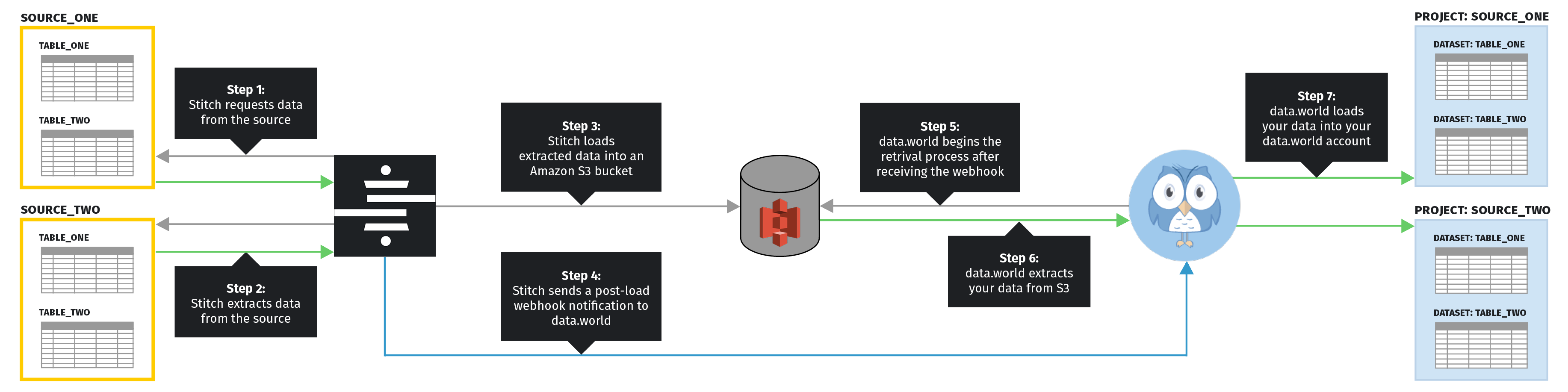
A Stitch replication job consists of three stages: Extraction, Preparation, and Loading.
The diagram below outlines the replication process for data.world destinations. In the following sections is more detail about what occurs during each stage in the replication process.
Click to enlarge
Extraction
During the Extraction phase, Stitch will check for structural changes to your data, query for data according to the integration’s replication settings, and extract the appropriate data.
Replication settings include the integration’s Replication Schedule, the data set to replicate, and the selected tables’ Replication Methods.
Preparation
During the Preparation phase, Stitch applies some light transformations to the extracted data to ensure compatibility with the destination.
In the case of data.world, the only transformation Stitch performs is inserting a few system columns into every table.
Loading
During Loading, Stitch loads the extracted data into the destination. Instead of loading data directly into your data.world account, Stitch will load the raw JSON data into an Amazon S3 bucket shared between Stitch and data.world.
After Stitch successfully finishes loading into S3, a webhook notification is sent to data.world to trigger the retrieval process. data.world will extract the data destined for your account and load it into your data.world account. Refer to the Schema section below for more info on how your data will be structured in data.world.
Replication Activity Report and Logs
To check in on the replication progress of your integrations, use the Extraction Logs and Loading Reports features, which are visible after clicking into the integration from the dashboard.
These logs and reports provide transparency into Stitch’s replication process such as info the progress of historical jobs and errors that occur during replication.
Note: Extraction Logs and Loading Reports are only available for certain integrations. Refer to the documentation linked above for info on supported integrations.
Schema
When data.world retrieves an integration’s data from the Amazon S3 bucket, it will be loaded into your data.world account as a project with child datasets.
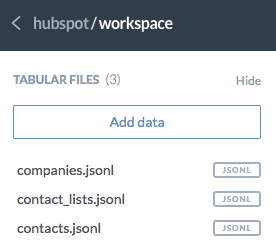
For each integration you connect to Stitch, a project with the same name will be created in data.world. The tables you set to replicate will be stored as JSON datasets within the project.
For example: If you named an integration HubSpot in Stitch and selected the companies, contact_lists, and contacts tables to replicate, your workspace in your data.world account would be the same as the image on the right.
Dataset Attributes
The dataset schema will contain the attributes you set to replicate in Stitch along with a few _sdc columns. These are system columns generated by Stitch for replicating data.
For information about the data available in SaaS integrations - including column descriptions and potential data values - refer to the Schema section of any of our integrations docs.
Nested Data Structures
All replicated data is stored as JSON, both in Amazon S3 and in data.world after the final load is complete. This means that nested structures are stored intact.
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.